Applied Data Science with Venture Applications
IEOR 135/ 290
Instructor: Ikhlaq Sidhu
Department of Industrial Engineering & Operations Research
3 Units, Lecture and Lab
Prerequisite: Interested students should have working knowledge of Python in advance of the class, and also should have completed a fundamental probability or statistics course. You can request the instructors to "revise my paper" to see if you are eligible for the course.
Teaching Team:
- Lead: Ikhlaq Sidhu, IEOR, [email protected]
- Visiting Scholar: Alexander Fred-Ojala, [email protected]
- GSI: Sana Iqbal: [email protected]
- Kevin Bozhe Li, [email protected]
- Blockchain: Nadir Akhtar, [email protected]
- Blockchain: Ali Mousa, [email protected]
Office Hours: Tuesdays 11am – 12pm, Etcheverry Hall 4176B (Breakout room)
Description
Course Description:
This course is designed primarily for upper-level undergraduate engineering and technical students. Graduate students at a mezzanine level can also take a co-located section of the course. The course material offers an understanding at the intersection of foundational math mathematical concepts and current computer science tools, with applications of real world problems. Math concepts include filtering, prediction, classification, decision-making, entropy as part of information theory, LTI systems, spectral analysis, and frameworks for learning from data. Computer science tools for this course include open source tools such as Python with Numpy, Scipy, Pandas, SQL, NLTK, Tensor Flow, and Spark. The course includes a team based data application project.
The lectures present alternating and related topics between mathematical frameworks and the same concept within code examples. One goal is that students who understand math concepts can bring them to life with scalable CS tools. And, students who are comfortable with computer software code can create systems by understanding selected, structured mathematical frameworks. This course is designed to be more applied than a traditional ML algorithms course as it includes a systems view and covers implementation concepts.
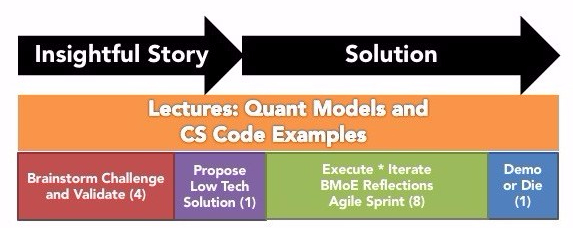
Applications of this course are broad. They include industry sectors such as finance, health, engineering, transportation, energy, and many others. The lab section of the course meets in parallel with the lecture. In the lab, the first 4 weeks are used to generate a story and low-tech demo for a real-world project that performs actions on data, and the following 8 weeks will be an agile sprint, with a demonstration of working project code by the end of the class. The skill set learned in this class can be applied to a broad range of industry sectors such as finance, health, engineering, transportation, energy, and many others.
Find our amazing projects from Fall-2017 here.
TEXTS AND REQUIRED SUPPLIES
- Hands-On Machine Learning with Scikit-Learn and TensorFlow By Aurélien Géron
- General Information
- Github for Code and Slides
- Anaconda Python Environment on personal computer
HOMEWORK, GRADING & ATTENDANCE
Class attendance and participation are expected, and sign-ins for sessions are tracked. Absences for unavoidable reasons should be preapproved whenever possible via an email to the GSI
Grading: (Required to be taken on Letter Grade only)
- Homework: 35%
- Attendance: 20%
- Low Tech Validated Solution 10%
- Final Project Demo, depth: 35%
Piazza
piazza.com/class/j6o5l788o874i
TENTATIVE SCHEDULE FOR SPRING 2018
- On a weekly basis, class sessions may start with a “meet a mentor” and/or “application model case study” section.*
- All slides and notebook samples will be updated at this site.
| Topic 1: | Introduction Theory: Overview of Frameworks for obtaining insights from data (Slides). Tools: Python Review |
| Code | 1. Introduction to GitHub 2. Setting up Anaconda Environment 3. Coding with Python Review |
| DUE | Homework 1 assigned. |
| Project | Office Hours Session that week for Environment Set Up |
| Topic 2: | Tools: NumPy, Pandas, Matplotlib |
| Code |
|
| DUE | HW 1 Due |
| Project | Bring 3 ideas to class. Mixer: Form teams for the final project. |
| Topic 3: | Theory: Data as a Signal with Correlation Tools: Webscraping – crawling and API use |
| Code | Coding with BeautifulSoup and other python scraping libraries |
| DUE | Homework -2 Due |
| Project | Form Teams Part II |
| Topic 4: | Theory: Prediction Algorithms Primer Tools: Scikit Learn for Classification and Regression |
| Code | Coding with Scikit Learn |
| DUE | Homework 3 Due |
| Project | Validate and Adjust |
| Topic 5: | Theory: 1. Introduction to Theory of Machine Learning 2. Regularization in ML – Overview Tools: Data Wrangling and Prediction in Python |
| Code | Coding with Pandas, Scikit Learn, Matplotlib on Titanic dataset |
| DUE | Homework 4 Due |
| Project | Low Tech Demo and Validation Results |
| Topic 6: | Theory: Introduction to Neural Networks- ANN, CNN, RNN Tools: Tensorflow |
| Code | Coding with Tensorflow for image classification |
| DUE | Homework 5 Due |
| Project | Agile sprint with reflection |
| Topic 7: | Theory: 1. Introduction to Natural Language Processing – NLTK overview and Word2vec 2. Sentiment Analysis Tools: NLTK, Gensim, Tensorflow |
| Code | Coding with NLTK, Gensim, Tensorflow |
| DUE | Homework 6 Due |
| Project | Agile sprint with reflection |
| Topic 8: | Theory: 1. Loss versus Risk 2. Theory of Decision Trees |
| Code | Coding with python |
| DUE | Homework 7 Due |
| Project | Agile sprint with reflection |
| Topic 9: | Theory: 1. Introduction to database 2. Introduction to SQL 3. Introduction to Block Chain as a database 4. Big Data Analysis with Spark Tools: SQL libraries in python, Solidity |
| Code | Coding with python for SQL and Spark |
| DUE | Homework 8 due. |
| Project | Agile sprint with reflection |
| Topic 10: | Theory: Spectral Signals, LTI -Fundamentals and Applications Tools: Temporal and Spatial Signal processing |
| Code | Coding with python for signal processing |
| DUE | Homework 9 Due |
| Project | Agile sprint with reflection |
| Topic 11: | Theory: Reinforcement Learning primer |
| Code | TBD |
| DUE | Homework 10 Due |
| Project | Agile sprint with reflection |
| Topic 12: | Project Presentations – Demo Day(s) |
| Code | Presentation including running code and code samples |
| DUE | Includes preparation time in last week |
| Project | Final Presentations |
- To include, if possible tool: Connecting Pandas to SQL for Long-term storage. AWS / SQL / Parallelization.
- Example application topics may include examples such as recommendation engines, digital mirror, customer journey, bloom filters, fuzzy join applications.
COURSE MODEL ILLUSTRATION: